Commvault
Business Continuity
Quick Links to Topics on This Page:
There are two concepts to consider when planning for disaster recovery and data protection:
- Business Continuity (BC)
- Disaster Recovery
Business Continuity (BC) Concepts
The concept of Business Continuity is the holistic approach of defining guidelines and procedures for the continuation of a business in the face of any disaster situation. From a technical aspect, high availability and Disaster Recovery relate to business continuity in the sense that a well planned and executed business continuity strategy includes both high availability and disaster recovery components. How and when high availability and disaster recovery strategies are put into place is based on the RTO and RPO values of each business-critical system.
Consider the following critical BC points and questions as they relate to DR planning:
- Facilities – How secure is the main data center? Is the air conditioner right on top of the data center? How reliable is the power source? Is there a generator? How often is it tested? How much fuel does it have?
- Chain of command – Who is in charge when the person in charge is not there? Who's next on the list? Who on the management team do you contact if you need to make substantial emergency purchase? What are ALL methods to contact ALL people in the chain?
- Communication – Who is our cellular provider and what are their contingency plans in the event of disaster? Who is responsible for communicating with them? In the case of disaster, how will management communicate with employees on status updates?
- Contingencies – What happens when Disaster Recovery plans need to be changed? How does the company deal with extended outages such as utilities where the ability to restore power or communication is out of the company's hands?
- Continuation of business – How will employees work if there is no facility to work from? How will they access resources? How will they communicate?
Business Continuity concepts showing management, high availability, and disaster recovery methods
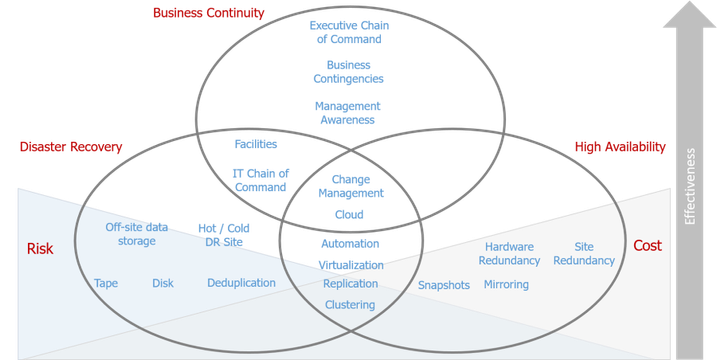

Building a Sound Data Protection Strategy
When building a protection plan, it is important to collect as much information as possible. The information can be classified in three main categories:
- Data Description
- Data Availability
- Protected Storage Requirements
Data Description
When designing a data protection strategy, it is important to assess entire business systems, not just servers. In today's data centers, it is very common for business systems to have many components including backend servers, front end servers, storage resources, and network resources. Consider all of these components in their entirety to properly define protection requirements.
Identify and Classify all Components of Business System
When surveying the business environment, all the components that make up a business system should be analyzed. Who owns the system, its value to the company, the cost of downtime, the cost of recreating data, cost of data loss, servers it runs on, storage it uses, networks it relies on, etc. Each component should also be classified as IT or business. Each classified component may require different protection and retention methods.
Business Classification
Data whose primary purpose is to directly support business functions is classified as Business Data Types. This would be the actual data being managed for business purposes such as email, financial databases, home folders, or web content. If this data is lost, it could cost thousands or even millions to recreate if it can be recreated at all. Although IT may manage the servers, the data owners are ultimately responsible for the business data. DBA's, managers, Chief Officers, VP's all invest a lot of time and money to build or purchase business systems which make their work more efficient and more profitable.
The loss of the data on these systems could be catastrophic. Rebuilding a database server is easier than recreating a lost database. Business systems may require different protection requirements than the core IT data on that same system. Compliance requirements may also require the data be kept for long time periods of time, encrypted, placed on WORM media, etc.
- Business data can be an entire system or component of system (e.g. critical database running on a database server or a sales tracking system in SharePoint).
- Business data can be containerized into subclients. These will be used to determine different SLA's for different business systems.
IT Classification
IT data classifications include operating systems, system databases, domain controllers, DNS servers, etc... This data does not directly serve a business purpose but it is the foundation in which business systems run. The primary purpose of protecting IT data is for Disaster recovery purposes. For example, a database server has a system database, some configuration files, and an underlying operating system which all qualify as IT data. There is also a financial database that runs on the server which is classified as business. This system may require different protection and retention methods that will be defined by its owner.
- IT systems that support business systems.
- Dependencies required for business system to function.
- Domain controllers.
- Network configurations including: routers, switches, VPN, and SAN configurations.
- Front end and back end servers.
Granular Classification of Business Data
Depending on protection and recovery requirements, business systems can be divided and categorized to meet very specific requirements. An email server would be classified as both IT and business. It must be protected for disaster recovery purposes, which is primarily a function of IT. The ability to recover or preserve specific mailboxes or mail databases is associated with business classifications. Using Commvault agents and subclients, different data can be containerized and protected to meet both business and IT requirements. This adds a level of administrative complexity but allows the administrator to implement solutions to meet business requirements.
Understand Value & Protection Requirements
The value of a business system determines protection requirements. Mission critical business systems have shorter Recovery Time Objective (RTO) and Recovery Point Objective (RPO) values. Financial and communication data may have longer retention and data preservation requirements. Each business system should be looked at granularly and protection requirements should be defined.
Gather Technical Data
Once the data has been classified, technical information must be gathered. Technical statistics in a well-organized and documented environment can be gathered through reports, documentation, and system analysis.
- Physical location of each component of the system
- Server location within physical or virtual environment
- Current data size and projected growth
Location of Data
The location of data relative to storage can greatly affect the performance of data protection operations. Is the data direct attached, network attached, SAN attached? Is the data on a physical or virtual server, local or remote location, local subnet, remote, or accessed over a VPN? These questions can affect the solution to protect the data. Snapshots might be better than traditional backups; replication may be better than relying on someone at a remote location to swap tapes, or locating a MediaAgent in closer proximity to the data to avoid remote backups
Size, Change and Growth of Data
Understanding current and future storage capacity needs is essential in determining where data should go, how long it can stay there for, and if additional investment in storage is required. Predicting and trending growth expectations can be accomplished through historical reporting and analysis tools. Estimating growth requirements can allow you to anticipate storage requirements which may alter your purchase decisions for more hardware or persuade decision makers to go with more efficient storage methods such as deduplication. Not planning for future requirements can result in adjusting protection requirements to fit capacity needs. That change in policy could have negative effects on you and your company later down the road.
System & Business Dependencies
This may be one of the most overlooked aspects of providing adequate protection for data. The simplest example would be protecting an Exchange server but not protecting your Domain Controller. The thought might be "We have so many domain controllers, we don't need to protect them." Then active directory becomes corrupt or a full site disaster destroys all your domain controllers. Your dependency required to rebuild your Exchange server is now unavailable. Granted this is an extreme example but it should be noted that dependencies and the time it takes to rebuild them will influence your recovery objectives. All system dependencies should be considered for all business systems.
Business dependencies can also be important. Consider the CFO who is the only person who knows a critical password which is required before a system can be rebuilt. Consider a Web provider who must perform actions on their end so remote users can access a database on your end. The point is, when it comes to system dependencies, you should leave no stone unturned. Figure out every dependency within your environment for each system.
Production and Storage Infrastructure
Where production data is located and its proximity to protected storage plays a large role in designing storage policies. The following section addresses the three key aspects of infrastructure:
- Production data location
- Library configuration and placement
- Data paths from production to storage
Production Data Location
The location of production data should be taken into consideration when planning MediaAgent placement and storage policy design. Large amounts of data being transmitted over a production network can not only slow down backup performance but also inconvenience end users (not to mention frustrate network administrators). Take the following into consideration for addressing the location of production data:
- Direct attached – data will require movement over the network when backing up data. If possible consider multi-homing the server and connecting it to a dedicated backup network.
- SAN attached – data can be protected using a LAN Free path if a MediaAgent is installed directly on the client. Consider using this approach when large amounts of data require protection.
- Network attached – storage can be backed up over the network or directly into a SAN if the NAS device is capable of SAN integration. The Commvault software supports either method.
- Remote data – can either be backed up over a WAN or a MediaAgent can be installed at the remote location. Using Commvault deduplication with client side deduplication would be the best method for protecting data over the WAN using minimal bandwidth. If a MediaAgent is at the remote location, using deduplication and DASH Copy allows data to be Auxiliary copied over the WAN using minimal bandwidth.
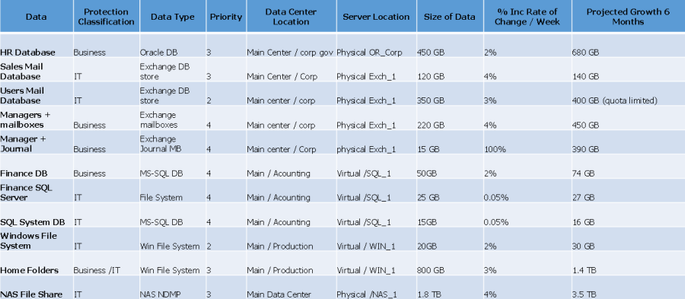
Chart sample for Data Description
Here is chart sample of the information that can be gathered about the data that requires protection. This can simply be reproduced in an Excel sheet, where you can segregate your data and compile information relative to it.
Data description chart sample
Data Availability
Determine Service Level Agreements
Service level agreements are used to establish protection and recovery windows and acceptable amount of data loss within those windows.
- Recovery Time Objectives
- Recovery Point Objectives
- Retention Requirements:
- On and off-site disaster recovery
- Data recovery
- Data preservation and compliance copies
Prioritize Data Type
Set priorities for different data types to establish its value to the company. For data protection, the priority levels will affect scheduling times, job priorities, and performance tuning to provide higher priority jobs with adequate resources. For recovery, a high priority data type can ensure certain business systems become available before others.
An example of data type prioritization would be dividing email databases into different subclients. Group higher priority mailboxes into smaller databases on the mail server and lower priority mailboxes into other databases. Consider a mail server recovery time if the total size of all databases was 600GB with mailboxes thrown into different databases with no rhyme or reason. Now consider that same server with the highest priority mailboxes in a small dedicated database about 60GB in size. The high priority database can be recovered first and the lower priority databases recovered later.
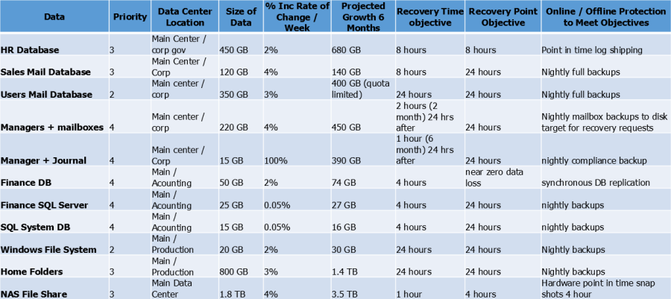
Chart sample for Data Availability
Here is the continuation of the previous chart sample. This chart displays columns related to data availability.
Data availability chart sample
Protected Storage Requirements
Identify Retention Objectives for Each Data Type
Retention objectives should be based on the three primary reasons for protecting data: Disaster Recovery, Compliance, and Data Recovery. Disaster recovery retention requirements are best to be handled by IT and should be based on how many complete sets or cycles should be kept. Compliance copies are usually point-in-time copies such as month end or quarter end and the retention should be based on how long the data needs to be kept for. Data Recovery may include all protected data within a time period (full and incremental) and the retention should be based on how far back in time data can be recovered.
Retention times can be customized for different business data types. For example, on an Exchange server there is a data recovery requirement for regular users to recover a deleted message for 60 days, but for sales people the requirement may be one year. By creating these different business data types, different retentions can be set to meet business requirements.
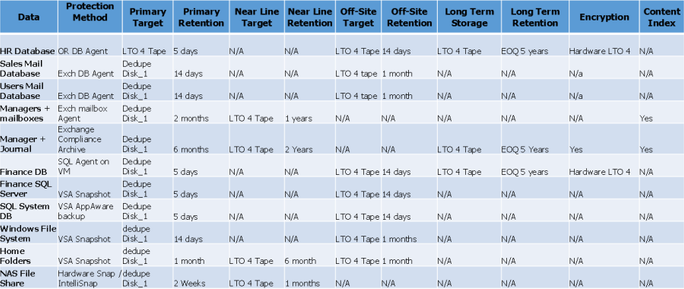
Chart sample for Storage Requirements
Here is the continuation of the previous chart sample. This time, it shows columns related to storage requirements.
Storage requirements chart sample
Design Methodology
Properly designing a CommCell® environment can be a difficult process. In some environments, a simple design may suffice, but in more complex environments, careful planning must be done to ensure data is properly protected and the CommCell® environment can properly scale to meet future requirements.
There are three phases to designing and implementing a proper solution:
- Plan
- Build
- Assess & Modify
The following highlights the key elements of each phase:
- The Planning Phase – focuses on gathering all information to properly determine the minimum number of storage policies required. Careful planning in this step makes it easier to build or modify policies and subclients. The objective is to determine the basic structure required to meet protection objectives. Modifications can later be made to meet additional requirements.
- There are three design methods that can be used during the plan phase:
- Basic Planning Methodology which focuses on generic guidelines to building storage policies and subclients.
- Technical Planning Methodology which focuses on technical requirements for providing a basic design strategy.
- Content Based Planning Methodology which takes a comprehensive end-to-end approach taking into consideration all aspects of business and IT requirements as well as integrating multiple technologies for a complete solution.
- The Build Phase – focuses on configuring storage policies, policy copies, and subclients. Proper implementation in this phase is based on proper planning and documentation from the design phase.
- The Modification Phase – focuses on key points for meeting backup/recovery windows, media management requirements and environmental/procedural changes to modify, remove, or add any additional storage policy or subclient components. It is important to note that the 'Design-Build-Modify' approach is a cyclical process since an environment is always changing. Not only is this important for data growth and procedural changes, but it also allows you to modify your CommCell environment and protection strategies based on emerging technologies. This provides greater speed and flexibility for managing protected data as our industry continues to change at a rapid pace.
Copyright © 2021 Commvault | All Rights Reserved.