Quick Links to Topics:
Credits:
Great thanks to Donato Sambucci and Robert Fowler for their technical expertise.
Deduplication V4 Gen 2 (V5) Overview
In SP14, Deduplication V4 Gen 2 (also referred to as Version 5) introduced major changes to the deduplication database; making it the most efficient deduplication generation to date. Performance has significantly improved the pruning of obsolete signatures and blocks of data. The performance of Deduplication database (DDB) reconstruction was also optimized to aid in the loss of DDB partitions.
DDB Structure Change
The improvements introduced in SP14 are based on a major structure change to the DDB tables and table files. To understand these changes, you must first look at the structure and roles of the tables.
DDB Structure Prior to SP14
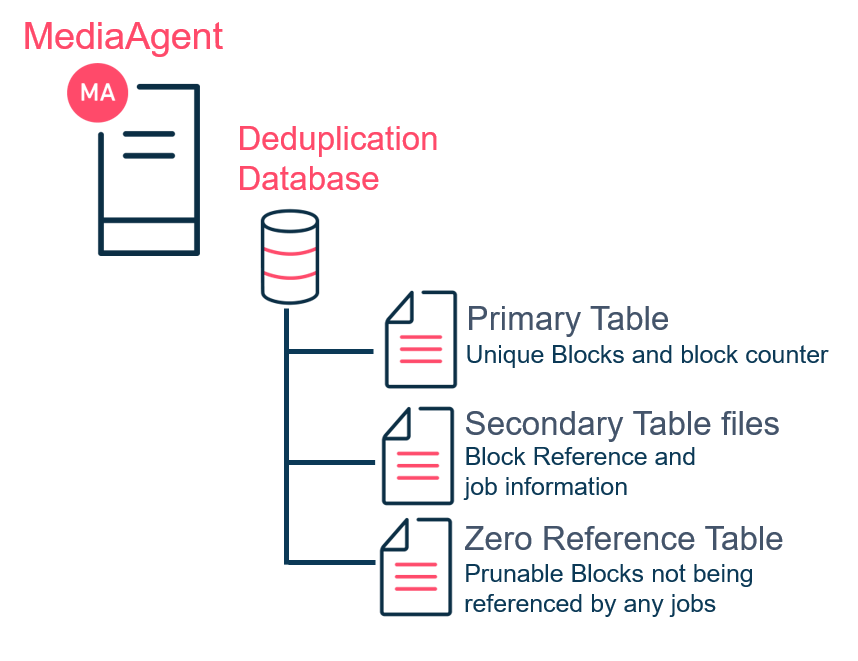
Prior to SP14, a DDB was created with three sets of tables:
- Primary table
- Secondary table
- Zero ref table
The DDB structure for a DDB created prior to SP14
Deduplication Database Prior to SP14:
The DDB primary table contains unique signature entries. Each entry represents a unique block of data encountered during a backup job. Each entry also has a counter indicating the number of occurrences for the unique block among all backup job stored in the deduplication store. This counter is increased each time the same signature is encountered during a backup job. The counter is decreased each time a job containing that block ages out. Once a counter reaches zero, the signature is moved to the zero ref table, which indicates that the block can be deleted from storage.
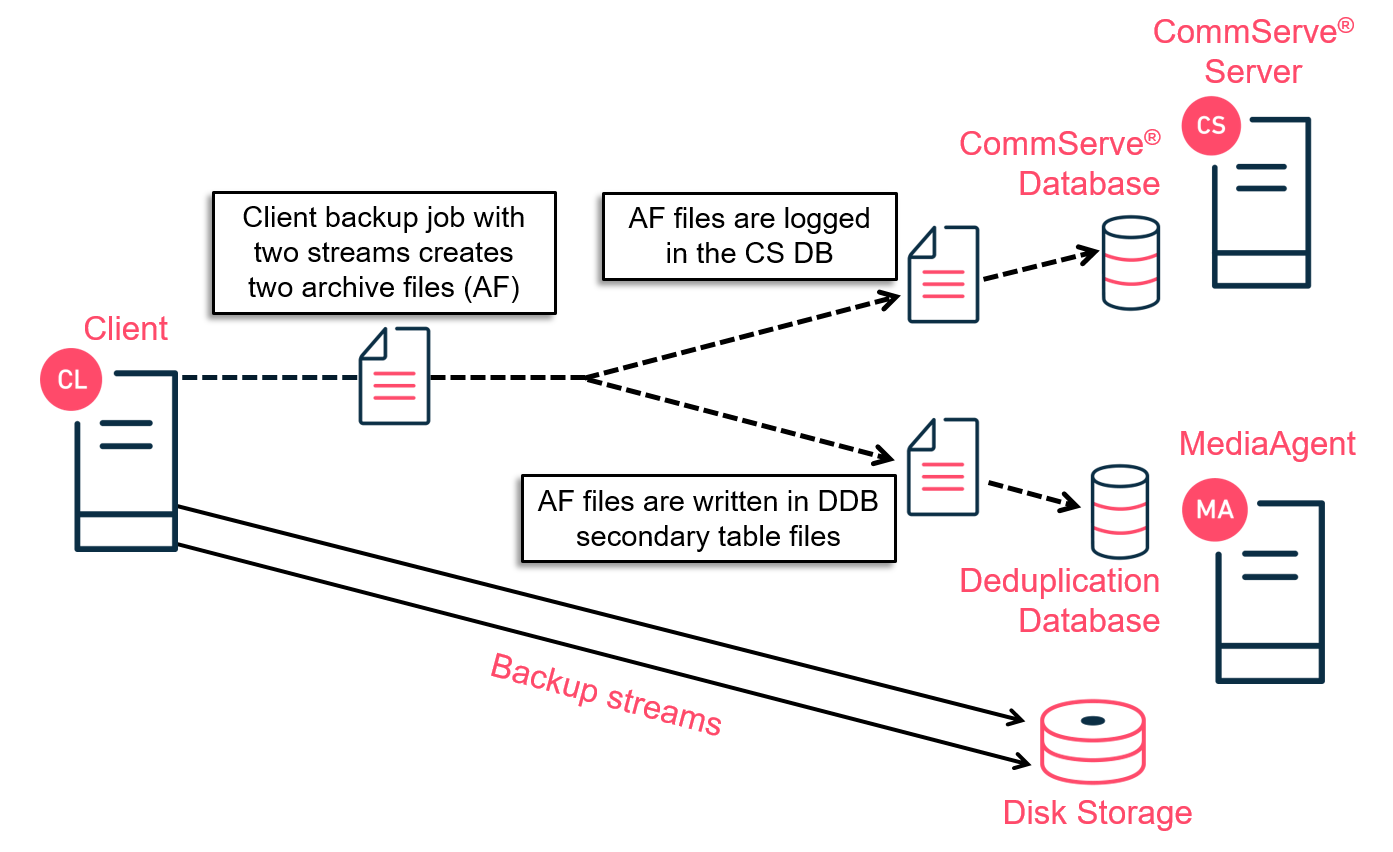
The DDB secondary table files stores archive file (AF) entries for all backup job streams. An archive file contains all the metadata of backup data covered in a job stream. This means that if a backup job has two streams, two archive files are created. The archive files are first logged into the CommServe® server database and written into a DDB secondary table file. The archive file contains block references and job information.
Representation of a backup job archive files
DDB V4 table structure

SP14 DDB Structure
With the introduction of the second generation of V4 deduplication, the table structure was modified for both the primary table and the secondary table files.
Primary Table
In the previous deduplication generation, the performance was impacted due to an increase or decrease of numerous counters when a backup job was running or aged out. This made the I/O process intensive. With DDB V4 Gen 2, counters are removed. When aging out data, secondary table files are scanned to create the list of obsolete blocks.
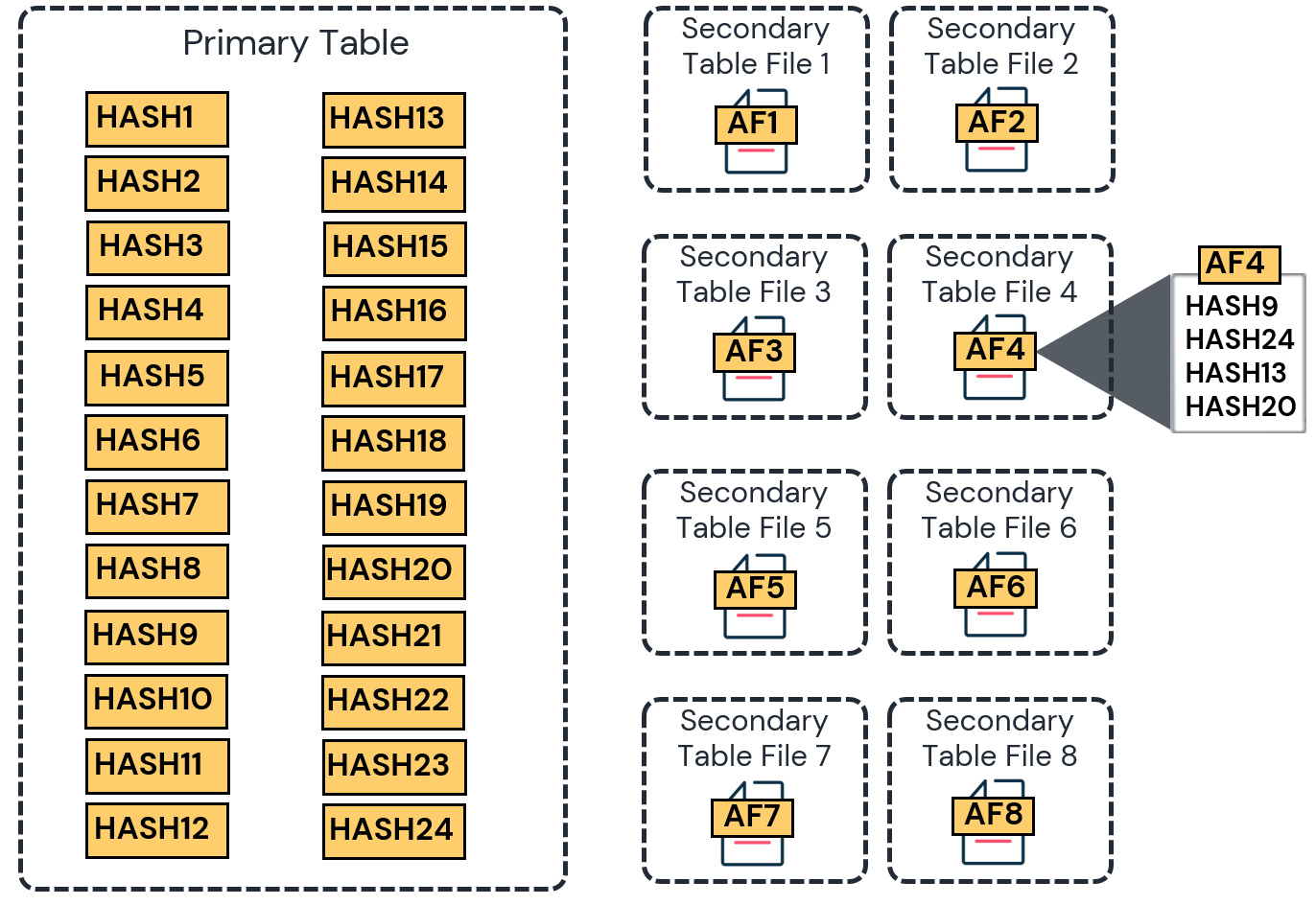
Secondary Table Files
In the previous deduplication generation, the DDB secondary table was built on files containing up to 16 archive files (AF). This means that as soon as the 16th archive file was written in the secondary file, the secondary file closed and a new one was created. This process continued creating as many secondary table files as were needed. In the new generation of deduplication, each archive file is now written as a standalone secondary table file.
DDB V4 Gen 2 table structure

Structure Change Advantages and Additional Improvements
The structure changes that were introduced in V4 Gen 2 improved many aspects of the deduplication database (DDB) operations:
- DDB reconstruction restartability
- Concurrent reconstruction for multiple DDB partitions (optional)
- Growth management
- Faster full and synthetic full backups
- Garbage collection (optional)
- Faster reconstruction (optional)
- Memory increase
- NVMe SSD optimization
Deduplication Database Reconstruction Restartability
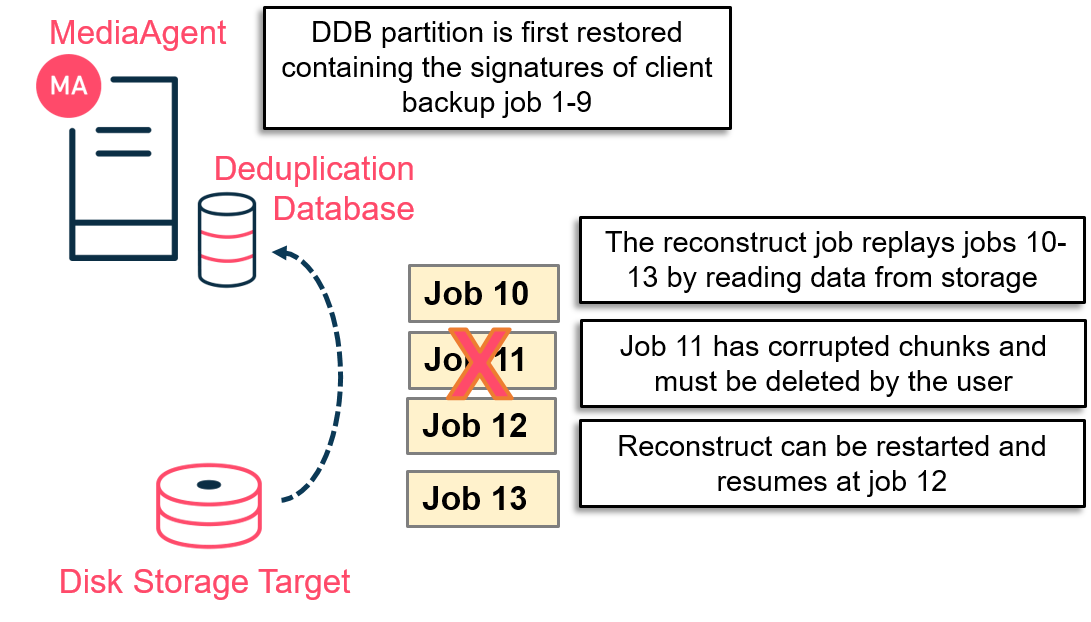
In the case of a corrupted DDB partition (e.g., disk failure, unplanned shutdown such as a blue screen), Commvault® software provides built-in reconstruction capabilities to bring the DDB partition back to its most current point-in-time. This reconstruction process consists of two main automated steps.
- The system restores the latest DDB backup, if available.
- The system 'replays' any client-server backup jobs that occurred since the last DDB backup was executed.
Replay Process
Replaying the missing jobs brings the database back to the last valid state before corruption. This replay is achieved by leveraging a basic function: the auxiliary copy. To recreate the missing entries in the deduplication database, an auxiliary copy job starts in the background. The copy reads the missing job's data from the Commvault®storage target without actually copying it anywhere, and during the process, it creates the missing signature entries in the DDB. With traditional DDB V4, if the process is interrupted it cannot resume.
Restartability Process
With DDB V4 Gen 2, a restartability process has been added. If the new generation is used, once the corrupted backup jobs are deleted and the reconstruction is restarted, the system picks up where the job failed without replaying the job already replayed. This saves a significant amount of time in larger environments because the auxiliary copy process now leverages the 'Scalable Resources' option. Not only does it provide restartability, it also improves CommServe® database performance and limits the TempDB growth during reconstruction.
Example of DDB reconstruction restartability
Growth Management
A major advantage of the new deduplication structure is the ability to mix short and long term retention of data within the same deduplication database.
IMPORTANT:
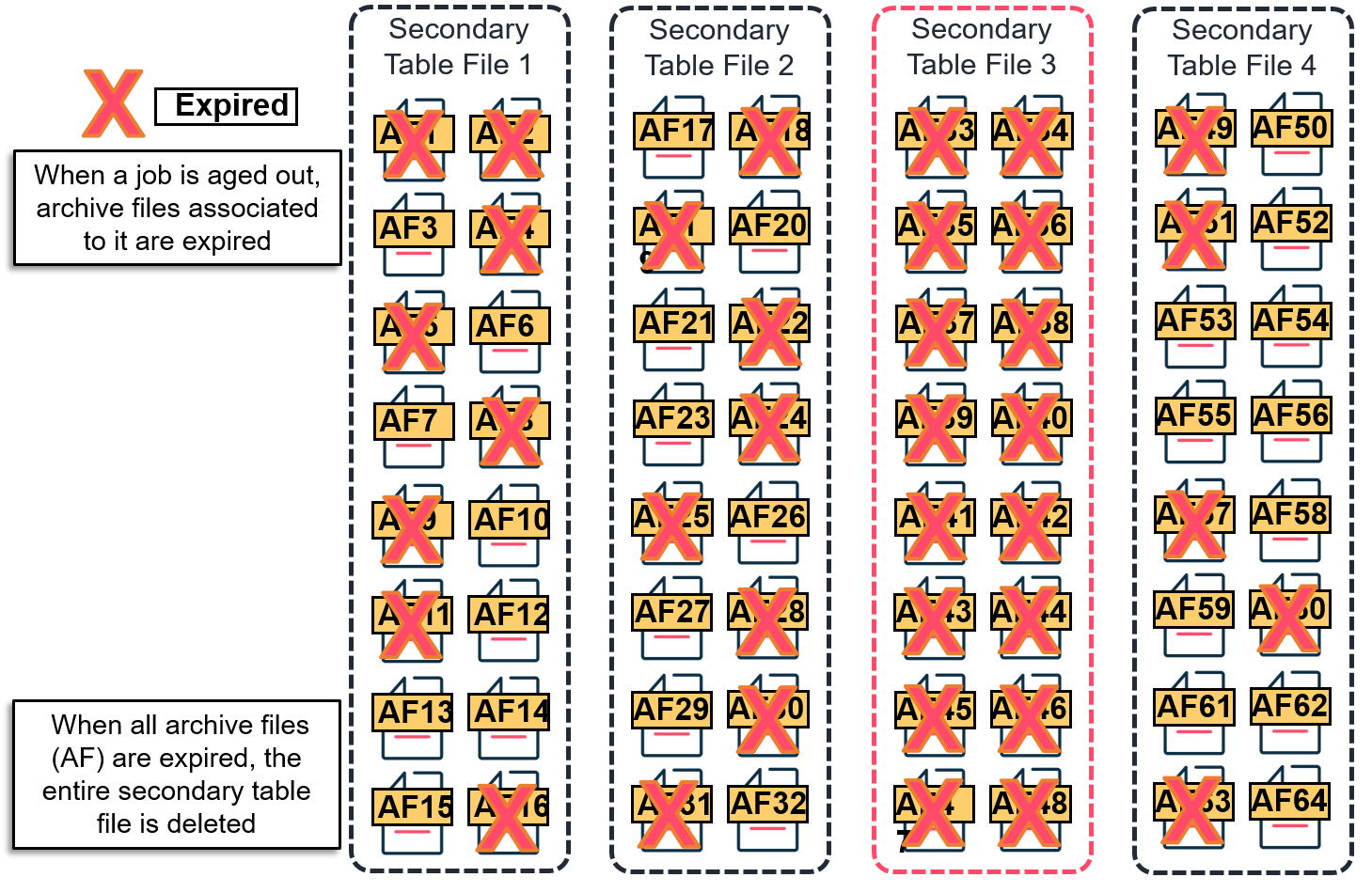
Although this function was available prior to SP14, it was strongly recommended NOT to mix retentions too far apart when creating a DDB. This was due to the old structure of the secondary table files; where each secondary table file stored up to 16 archive files. The archive file was retained in the table file for as long as the job it was referring to existed. Once the job expired, the archive file associated with it is also expired.
Scenario: Consider a DDB with a mix of long term and short term retention: a table file may frequently store archive files with a mix of retention. The short term archive files with short term retention will expire first. But all archive files within a secondary table file must be expired in order to delete the entire table file. This means that table files containing long term archive files are not deleted until that data also expires. Oftentimes this leads to a situation where the size of the DDB grows exponentially due to undeleted secondary table files.
DDB V4 with a mix long term and short term retention
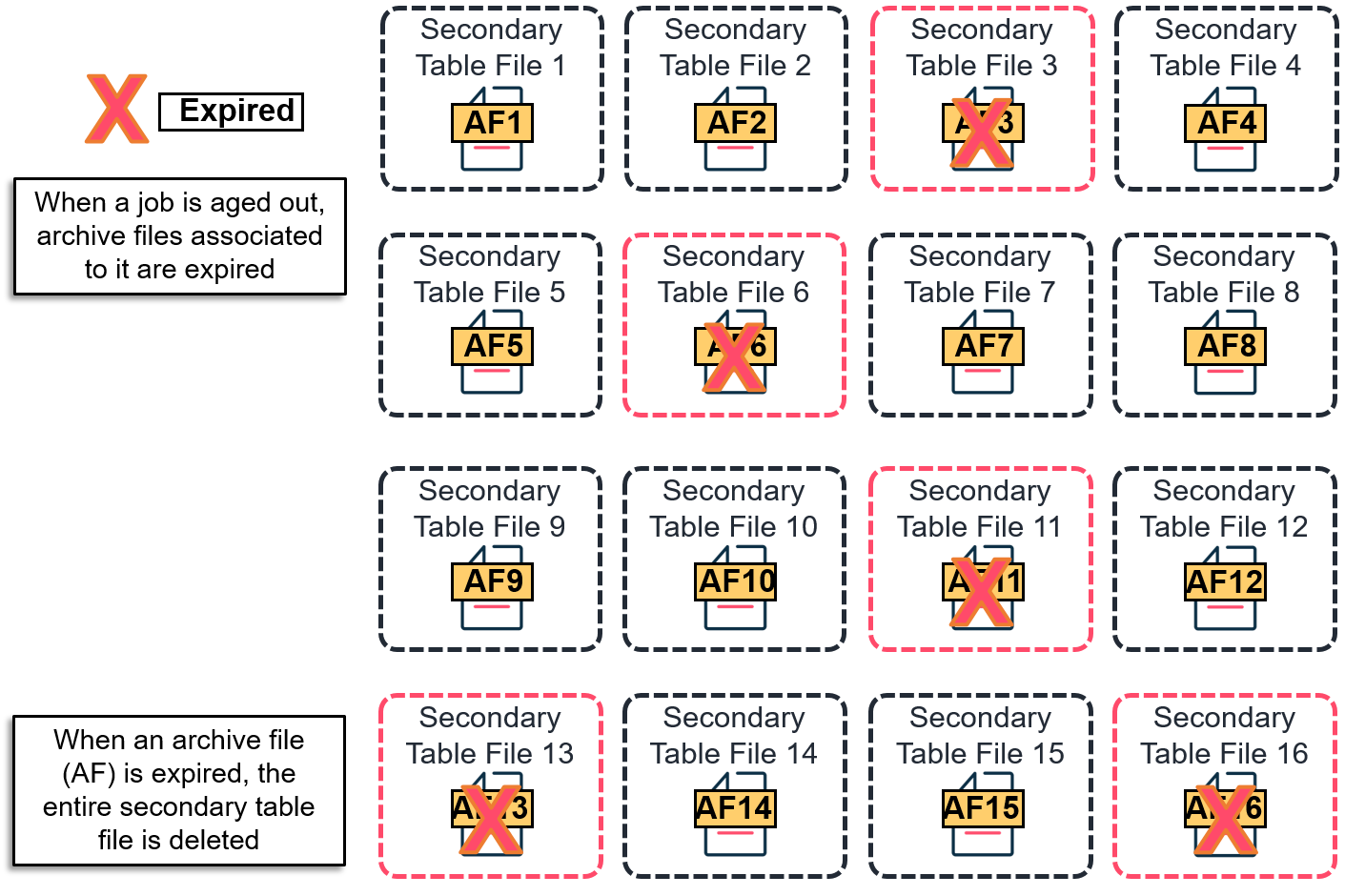
A DDB created after SP14 uses the new generation of deduplication. Each archive file is saved in a separate secondary table file and is deleted on a per-archive file basis upon expiration. This avoids any unwanted increase in DDB size, even when mixed retention is used. There is no need to separate short term and long term data in a different deduplication database, which can lead to a complete rebaseline of the data.
DDB V4 Gen 2 with a mix of long term and short term retention
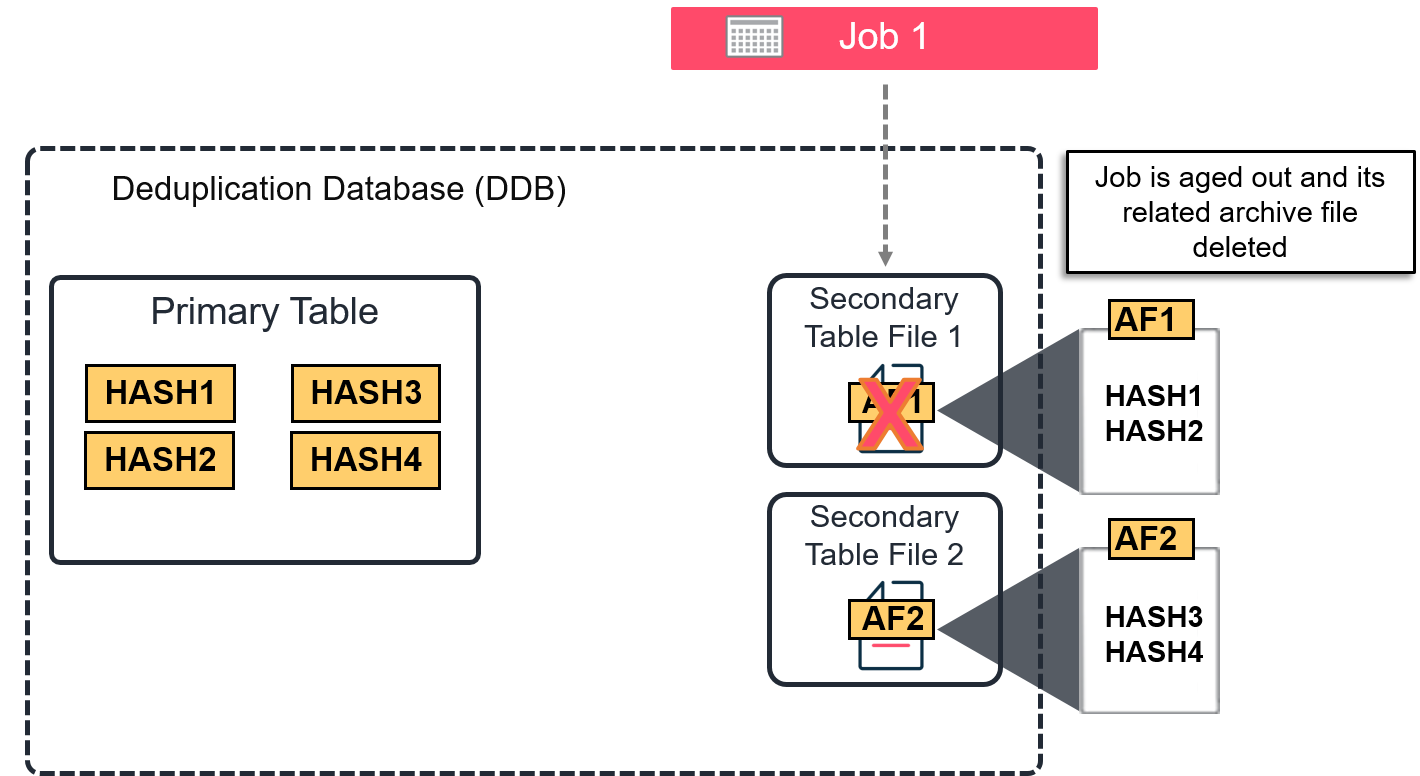
Garbage Collection (Mark and Sweep)
The Garbage Collection, which is also referred to as "Mark and Sweep," is an opt-in feature that speeds up the data aging and pruning process of a V4 Gen 2 DDB. A new DDB no longer relies on signature reference counters to age out signatures. Instead, the secondary table files are scanned sequentially and compared with signatures from the primary table. Any signature present in the primary table that is no longer referenced by any secondary table file is moved to the zero ref table and therefore is a candidate to be purged from storage.
When the Mark and Sweep option is enabled, the intermediate information generated when collecting expired signatures is logged in a bitmap memory cache. The zero ref table is then updated with the information from the bitmap file.
Logical representation of the Mark and Sweep option
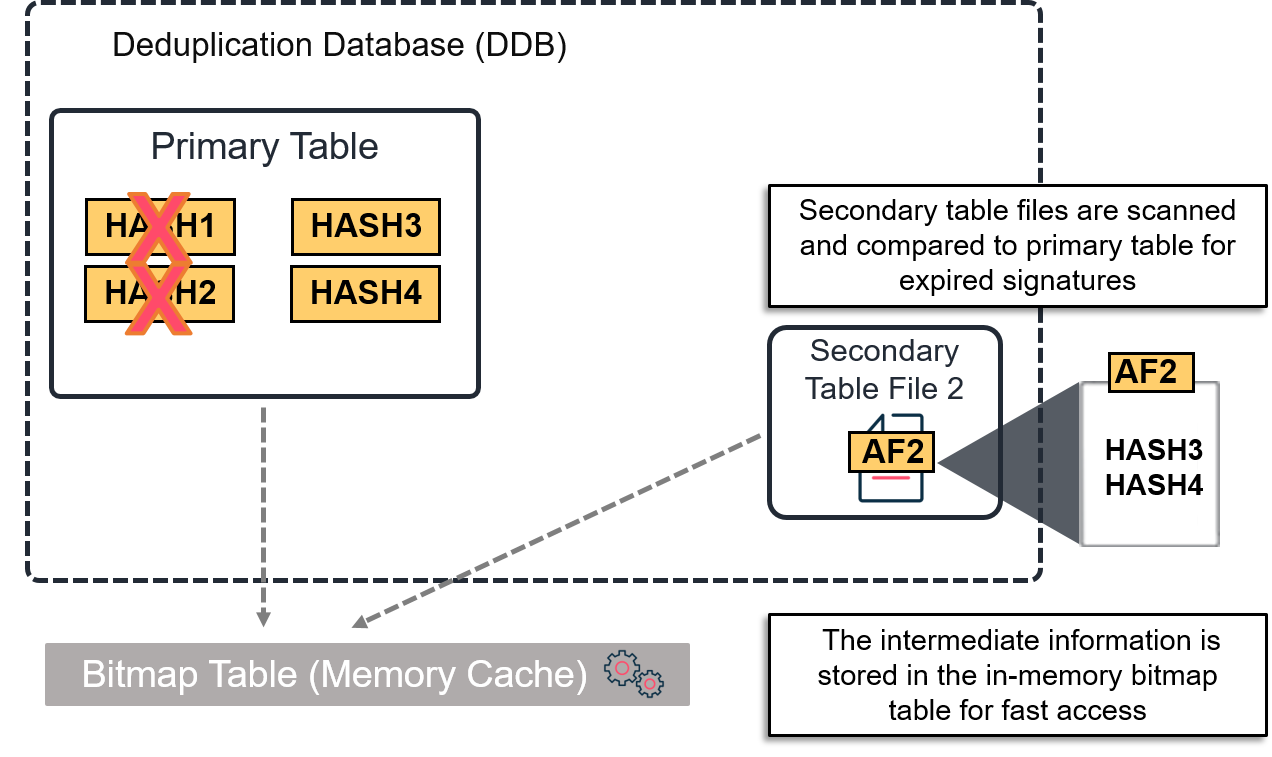
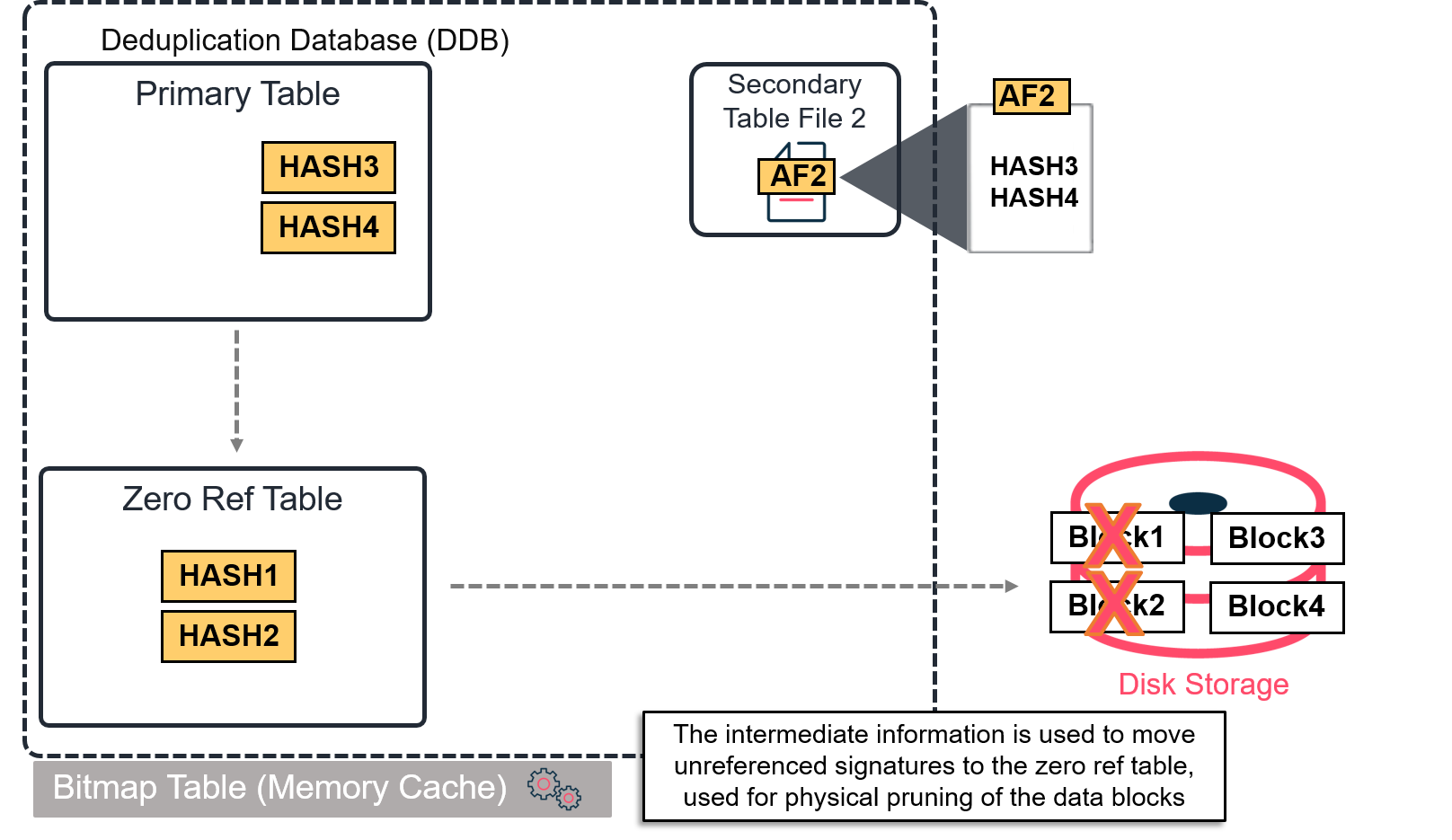
Enabling Garbage Collection
The 'Garbage collection option' must be enabled on a new global deduplication policy before running any backups. The 'Enable garbage collection' is enabled by default. From the Global Deduplication Storage Policy Properties page, enable the "Garbage collection' option.
Once enabled, the garbage collection option cannot be disabled. The collection runs every 24 hours after the time it was enabled. For existing deduplication databases created before SP14 or already containing backup data, the Mark and Sweep option can also be leveraged, but some crucial prerequisite tasks must first be performed. They are as follows:
- Run a DDB backup to protect all the partitions of the deduplication database
- Stop the MediaAgent services
- Compact the DDB partitions (explained below)
- Start the MediaAgent services
- Run another DDB backup
- Enable the garbage collection option
The compaction operation must be performed on each DDB partition. The commands transform the secondary table file structure, resulting in a single archive file per secondary table file. It also drops the signature reference counters from the primary table.
Compaction command syntax:
sidb2 -compactfile secondary -i <DDB_ID> -split <split_number>
| Options | Descriptions |
|---|---|
| -compactfile secondary | The keyword to create a single archive file per secondary file. |
| -i | The partition number of the DDB. You can view the split number by accessing the path of the DDB.
|
| -split | The partition number of the DDB. You can view the split number by accessing the path of the DDB. For example, in the following location, the split number is 01. E:\<DDB Folder>\CV_SIDB\2\86\Split 01 |

Caveats:
- Garbage collection CANNOT be enabled on Transactional DDB
- For Commvault HyperScaleTM environments, garbage collection can only be enabled on the newer environment (SP14 and earlier).
Once the DDB partitions are compacted and the final DDB backup executed, the garbage collection option can be enabled.
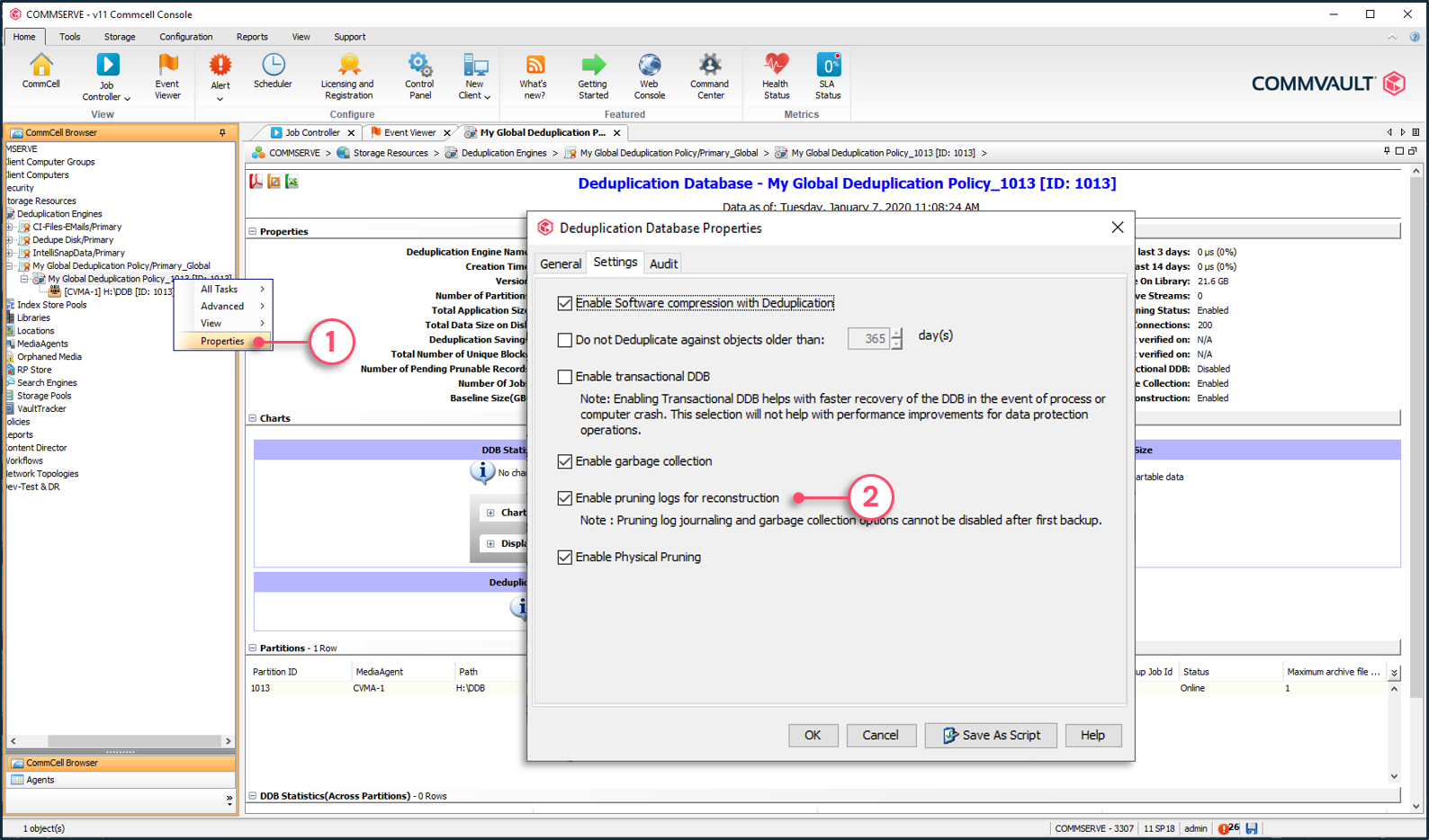
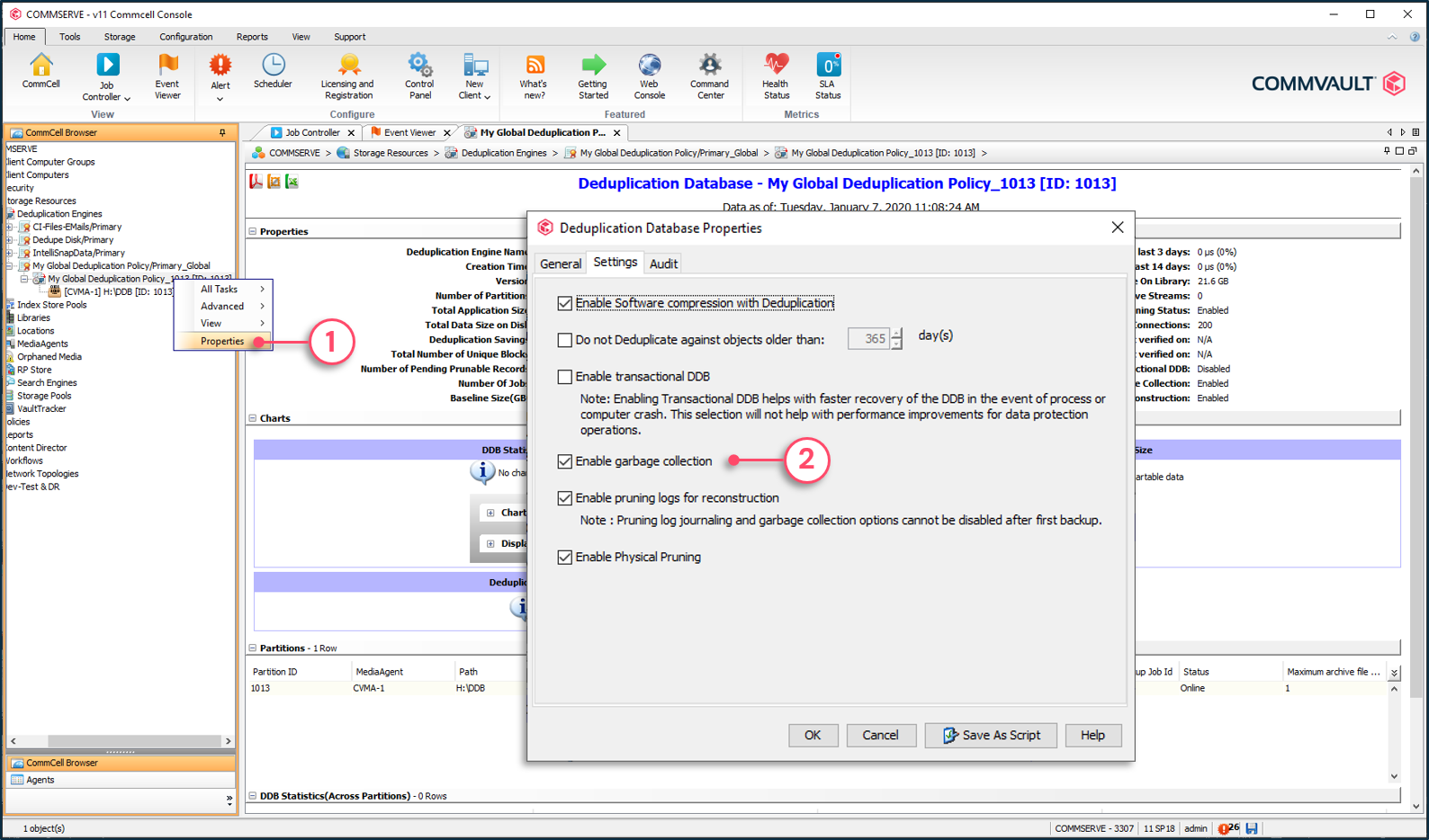
To enable garbage collection
1 - Right-click the deduplication engine and select Properties.
2 - Check the option Enable garbage collection.
Garbage Collection Troubleshooting Tips
The garbage collection option is not that verbose when using the default debug level. But, there are some entries that can be used to monitor the behavior of the Mark and Sweep process:
The first entry is in the SIDBEngine.log file. An entry is added showing when the last Mark and Sweep operation ran.
Log entry for the last execution of the mark and sweep process:
920 1960 01/30 17:01:33 ### 134-0-194-0 MSOpen 13649 Mark And Sweep. Last Run [Wed Jan 30 01:01:31 2019]
Garbage collection runs every 24 hours from the time it was first enabled. However, it will start only if there is files logically deleted on the MediaAgent. An entry in the SIDBEngine.log file indicates if files were deleted.
If it displays:
- Pruning Hint (1): Files were deleted and therefore the garbage collection will start.
- Pruning Hint (0): No files were logically deleted and the garbage collection operation will simply be skipped.
Log entry for deleted files:
920 1960 01/30 17:01:33 ### 134-0-194-0 MSReadCfg 13538 Mark And Sweep. Build Bloom [1], Max Bmp Elems [68719476736]
920 1960 01/30 17:01:33 ### 134-0-194-0 MSReadProps 11961 Use Ref Count [0], Phase [0], Last Run Time [1548828091], Pruning Hint [0], Building bloom [0]
920 1960 01/30 17:01:33 ### 134-0-194-0 MSReadProps 11962 Restart string []
To enable garbage collection
1 - Right-click the deduplication engine and select Properties.
2 - Check the option Enable pruning logs for reconstruction.